






4 Min. Lesezeit

Zusammenfassung
Case Study am Beispiel eines international operierenden Logistik-Konzerns mit Standorten rund um den Globus. Im Zusammenspiel von AWS und Atlassians Data Center-Deployment wird ein extremer Performance Boost erreicht. Unserem PoC wurde von den Solution Architekten von Atlassian und AWS bescheinigt, die derzeit beste Lösung zu sein.
Aufgabe und Proof of Concept
Ein weltweit agierendes Logistik-Unternehmen mit über 30.000 Mitarbeitern steht vor der Herausforderung, business-kritische Anwendungen (Jira Software, Confluence usw.) mit geringen Latenzen erreichbar zu machen. Massiver Painpoint: zu schlechte Performance im weltweiten Einsatz. Inklusive der berüchtigten so genannten Jira Kaffee-Pause an Standorten in China und den USA. Die Applikationen werden on-premise im eigenen, deutschen Rechenzentrum betrieben.
Bei dem Projekt war es die Aufgabe, den Beweis anzutreten, dass AWS-Instanzen in Kombination mit dem Atlassian Data Center-Deployment einen massiven Performance-Boost bringen kann. Unsere Proof of Concept-Instanzen fütterten wir mit einem 40 GB-Datenbankdump, um realistische Ergebnisse zu erzielen.
Das Ergebnis: Bis zu 10x bessere Performance, weltweite Hochverfügbarkeit und Zero Downtime. Solution Architekten von AWS und Atlassian waren eng in die Entwicklung eingebunden und bescheinigen dem Setup, dass es die derzeit bestmögliche Lösung ist.
Unsere Lösung: Data Center-Setup und die passende AWS-Infrastruktur
Aktuell ist ein Multi-Region Deployment von AWS mit den Atlassian-Applikationen nicht möglich. Um dennoch den gewünschten Performance-Boost zu erreichen, wird AWS Cloudfront als Cache für den statischen Content genutzt.
Die AWS-Experten der demicon entwarfen in Absprache mit dem Kunden ein erstes Grobkonzept, um alle Anforderungen abzubilden. Als Atlassian Platinum Solution Partner und AWS Consulting Partner wurde der direkte Draht zu AWS und Atlassian genutzt, um Solution Architekten einzubinden. Damit stellten wir sicher, dass unser vorgeschlagenes Setup auch tatsächlich das bestmögliche Ergebnis darstellt.
Ziele PoC und Setup
Der PoC sollte folgende Punkte aufzeigen:
- High Availability durch ein Data Center-Deployment
- Geringere Latenzen für die einzelnen Standorte durch ein Multi-Region Ansatz bei Amazon Web Service (Insbesondere wichtige Standorte klagten über sehr hohe Latenzen im vorhandenen Setup)
- Analyse Total Cost of Ownership: Vergleich On Premise-Ansatz und Cloud
Nach der Aufnahme der Requirements entwickelten die Cloud-Architekten entsprechend der beschriebenen Vorgaben den PoC.
Der erste Vergleich der beiden Systeme (Kundensystem vs. AWS-Deployment) lieferte bereits sehr beeindruckende Zahlen: Die Ladezeiten wurden auf ein Viertel der Zeit verkürzt und das Laden vom Dashboard sogar auf nur noch ein Fünftel der vorherigen Zeit.
Um diese Zahlen zu untermauern und aus einer Laborumgebung eine realitätsnahe Umgebung zu schaffen, wurden im nächsten Schritt die kompletten Datensätze (rund 40 GB) aus dem vorhandenen System hochgeladen, um das System mit der gleichen Last zu testen.
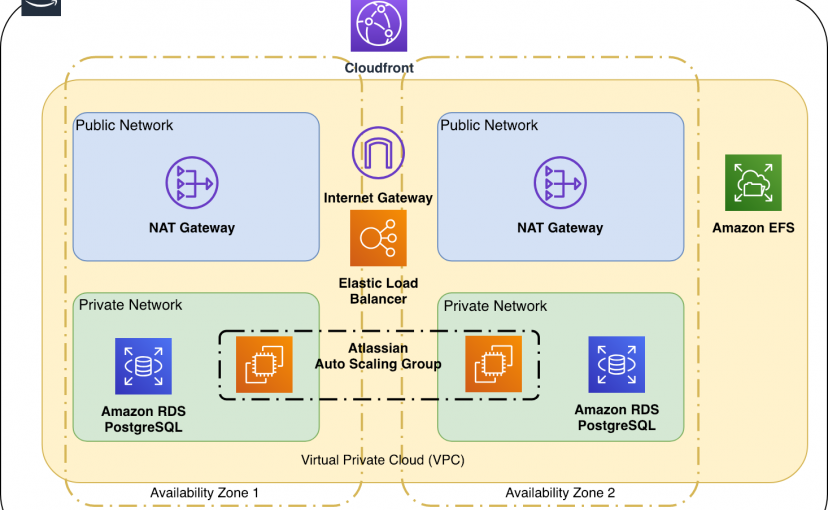
Technische Details
Setup Infrastruktur
- AWS EC2 t2.micro als Bastion Host / Jumpbox im öffentlichen Subnetz
- AWS RDS PostgreSQL im Multi Region deployment
- AWS EC2 Zwei C5.xlarge als Datacenter Nodes im private Subnetz
- AWS EFS als Datastore für Attachments und Plugins
- AWS ELB als Loadbalancer für das skalieren und die Hochverfügbarkeit
- AWS Launch Configurations und Auto Scaling Groups
- AWS Cloudfront als CDN
Direkt hinter dem CDN wird ein AWS ELB (Elastic Load Balancer) eingesetzt, der den Traffic annimmt und an die Nodes über ein AWS NAT-Gateway verteilt. Der Load Balancer macht hier auch die Healthchecks und schickt Traffic nur an "gesunde" Nodes. Im Falle eines Ausfalles einer Node wird der Traffic komplett auf den noch vorhandenen Node umgeleitet.
Automatisierte Healthchecks und Autoscaling nach Bedarf
Sobald durch einen Healthcheck bemerkt wurde, dass eine Node ausgefallen ist oder die Last auf einem Node zu hoch wird, erfolgt das Hochfahren durch die Autoscaling Groups und die Launch Configuration einer neuen Node. Diese wird nach erfolgreichem Healthcheck automatisiert in den Load Balancer eingebunden. Bei einem Ausfall einer Node wird diese automatisch aus dem Load Balancer entfernt.
Die Application Nodes sind von außen nicht direkt erreichbar und liegen in einem privaten Subnetz. Man erreicht die Application Node nur über einen sogenannten Bastion Host / Jumpbox. Die Jumpbox befindet sich im öffentlichen Netz und wird durch AWS Security Groups und Network ACL's abgesichert. Hier ist nur der Port 22 für SSH aus dem Netz der Demicon erreichbar. Ausserdem ist der Bastion Host nur per SSH-Key Accessible.
Die eigentlichen Daten befinden sich in einem AWS RDS mit Postgres welches in einem Muti-Availability Zone Deployment läuft. Im Falle eines Ausfalls einer AZ wird automatisch der Traffic zur Backup DB umgeleitet, welche sich in einer anderen Availability Zone (AZ) befindet. Hierdurch ist es möglich, einen Ausfall einer kompletten AZ abzufangen - ohne spürbare Beeinträchtigungen.
Ausblick AWS Aurora
Atlassian hat die Nutzung von AWS Aurora auf der Summit 2019 in Las Vegas angekündigt. Sobald eine Freigabe erfolgt ist, könnte hier noch einmal ein weiterer Performance-Boost entstehen. AWS Aurora ist bis zu 10 Mal schneller als eine normale PostgreSQL DB und hat bis zu 15 Read Replicas.
Für Attachments und Plugins (Apps vom Atlassian Marketplace) wird ein Netzwerkspeicher (AWS EFS) eingesetzt. Durch den Einsatz des Netzwerkspeichers sind die eigentlichen Nodes somit ohne relevante Daten und können ausfallen oder zerstört werden ohne einen Datenverlust zu erleiden. Hier ist nun auch kein Nachjustieren der Größe einer Festplatte von Nöten, da AWS EFS mit den Anforderungen des Systems mitwächst. Bei herkömmlichen Festplatten muss eine explizite Größe angegeben werden und sollte es zum "Volllaufen" einer Platte kommen, muss diese vergrößert werden. Mit AWS EFS muss bei der Konzeption nicht auf die Datenmengen geschaut werden.
Scaling-Out
Allein durch ein flexible AWS-Setup in Kombination mit dem Data Center-Deployment von Atlassian können Hosting-Kosten eingespart werden. Zwar können für die Applikationen je nach Bedarf und steigender Last zusätzliche Nodes automatisch hinzugefügt werden, doch zugleich funktioniert dies auch in die andere Richtung. Mit Scaling-Out kommen nur die Ressourcen zum Einsatz, welche tatsächlich benötigt werden.
Wir empfehlen, dass immer mindestens zwei aktive Nodes vorhanden sind und diese auf verschiedene AWS Availability Zones verteilt werden. Dies gewährleistet eine hohe Ausfallsicherheit, da der Load Balancer bei Ausfall einer Availability Zone den Traffic direkt auf einen andere aktive Node umleitet. Parallel hierzu würde eine neue Node hochgefahren werden, welches in etwa 2-5 Minuten dauert, und dem Load Balancer mitgeteilt werden sodass die Lastenverteilung dann wieder auf mehrere Nodes stattfindet. Unsere Erfahrung hat allerdings gezeigt, dass der Ausfall von mehr als einer Zone noch nie vorgekommen ist und somit auch der Ausfall von nur maximal einem Node in der Praxis möglich ist.
Keine Zeit für RTO und RPO - Just in time Recovery
Weiter ist ein Restore der Daten bis auf das letzte ausgeführte Kommando möglich. Keine RTO- und RPO- Zeiten.
Just in time Recovery.
Vorteile eines Proof of Concept
Ein Proof of Concept liefert Ihnen nicht nur theoretische Annahmen, sondern konkrete Resultate. Nach dem ersten Grobkonzept erstellen unsere Cloud Architekten eine für Sie passende Infrastruktur. Die bereitgestellte Installation wird als leere Instanz zur Verfügung gestellt, in der dann getestet und Testdaten eingegeben werden können. Sollten Sie gerne einen Teil oder alle Ihre Daten testweise auf die PoC-Umgebung migrieren wollen so ist dies auch möglich.
Lassen Sie sich vom Proof of Concept überzeugen – die Vorteile liegen auf der Hand:
- Ausfallsicher mit 99,99%
- Hochverfügbarkeit und Performance-Steigerung
- Disaster Receovery und Business Continuity wird von Amazon Web Services gewährleistet
- Deutliche Einsparungen bei den Betriebskosten: wir berechnen mit Ihnen die Total Cost of Ownership

CHRISTOPHER GRAF
Head of Account Management
Sie haben Fragen oder wünschen eine persönliche Beratung? Unser Experte hilft Ihnen gerne weiter.
Jetzt anfragen!
